FreeRTOS
FreeRTOS操作系统
简介
FreeRTOS is a mini real-time operating system kernel.
As a lightweight operating system, its functions include: task management, time management, semaphores, message queues, memory management, recording functions, software timers, coroutines, etc., which can basically meet the needs of smaller systems.
FreeRTOS can run on small RAM microcontrollers. The FreeRTOS operating system is a completely free open source operating system. It has the characteristics of open source code, portability, reduction, and flexible scheduling strategy. It can be easily transplanted to run on various microcontrollers.
The Armino platform currently uses the version released in July 2021, a Release version slightly newer than the 10.4 LTS version (FreeRTOSv202107.00), version number: FreeRTOS Kernel V10.4.4
FreeRTOS general architecture
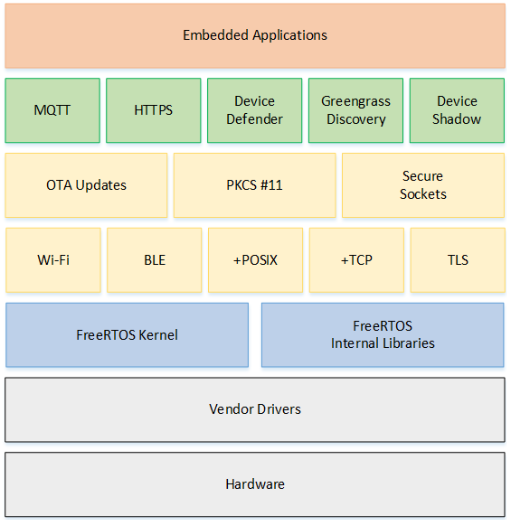
FreeRTOS architecture
A FreeRTOS system is mainly composed of BSP driver + kernel + components (as shown in the picture above). The kernel includes functions of multi-task scheduling, memory management, and inter-task communication, and components include network protocols, peripheral support, etc.
The FreeRTOS kernel is tailorable and components are optional. Since embedded applications often have very strict requirements on memory space, a tailorable RTOS is very important for embedded applications. This makes the core code of FreeRTOS only about 9,000 lines.
Functions and features
User configurable kernel features
Multi-platform support
Provides a high level of trust in code integrity
The target code is small, simple and easy to use
Follow the programming specifications of MISRA-C standard
Powerful execution tracking function
Stack overflow detection
Unlimited number of tasks
Unlimited task priority
Multiple tasks can be assigned the same priority
Queues, binary semaphores, counting semaphores and recursive communication and synchronization tasks
Priority inheritance
Free and open source source code
FreeRTOS Summary
As a lightweight operating system, FreeRTOS provides functions including: task management, time management, semaphores, message queues, memory management, recording functions, etc., which can basically meet the needs of smaller systems. The FreeRTOS kernel supports a priority scheduling algorithm. Each task can be assigned a certain priority based on its importance. The CPU always allows the task in the ready state with the highest priority to run first. The FreeRTOS kernel also supports a rotation scheduling algorithm. The system allows different tasks to use the same priority. When there is no higher-priority task ready, tasks of the same priority share the CPU usage time.
The kernel of FreeRTOS can be set as a deprivable kernel or a non-deprivable kernel according to user needs. When FreeRTOS is set as a preemptive kernel, high-priority tasks in the ready state can deprive low-priority tasks of CPU usage rights, which ensures that the system meets real-time requirements; when FreeRTOS is set as a non-preemptive kernel , high-priority tasks in the ready state can only be run after the currently running task actively releases the right to use the CPU, which can improve the operating efficiency of the CPU.
In the embedded field, FreeRTOS is one of the few embedded operating systems that has the characteristics of real-time, open source, reliability, ease of use, and multi-platform support. At present, FreeRTOS has developed to support up to 30 hardware platforms including X86, Xilinx, Altera, etc., and its broad application prospects have attracted more and more attention from industry insiders.
FreeRTOS SMP Architecture
SMP Summary
The Armino platform uses the FreeRTOS SMP architecture with the kernel code path: components/os_source/freertos_smp_v2p0
When it comes to multi-processor systems, Symmetric Multiprocessing (SMP) is a common architecture
BK7258 supports the FreeRTOS SMP architecture, running on physical CPU1 and CPU2
Here is a brief introduction to the basic concepts of SMP, the purpose and advantages of implementing SMP in FreeRTOS
Symmetric Multiprocessing(SMP)
Multiprocessor Systems: - A multiprocessor system is a computer system composed of multiple processing cores. Each processing core can independently execute tasks and run programs.
Symmetric: - In an SMP system, all processing cores have a symmetric position, meaning they can all execute the same tasks and access the same system resources (including peripherals and memory).
Shared Memory: - In an SMP system, the processing cores communicate with each other by sharing the same memory space. This makes data sharing easier, but also requires measures to be taken to prevent issues such as race conditions.
The purpose and advantages of implementing SMP in FreeRTOS
Improving Performance: - SMP allows multiple processing cores to execute tasks simultaneously, thereby improving the overall system performance. Especially when handling a large number of parallel tasks, SMP can effectively distribute the workload and accelerate the system’s response speed.
Task Parallel Execution: - In an SMP system, different processing cores can independently execute different tasks. This parallelism helps to improve the system’s throughput and responsiveness.。
Better Resource Utilization: - SMP allows the system to execute tasks simultaneously on different processing cores, effectively utilizing hardware resources. This is particularly important for handling real-time tasks and applications that require high performance.
System Flexibility: - The SMP architecture makes the system more flexible, allowing it to scale up its processing capabilities as needed. Increasing the number of processing cores can simplify the system’s upgrade and maintenance process.
Real-Time Performance: - For real-time operating systems like FreeRTOS, the implementation of SMP can provide better real-time performance, ensuring that tasks are executed within the specified time frame, thus meeting the requirements of real-time systems.。
Implementing SMP in FreeRTOS requires consideration of challenges such as inter-processor synchronization, shared resource management, and task scheduling. However, with correct implementation, it can significantly improve the system’s performance and responsiveness.
Scheduling Strategies in FreeRTOS SMP Architecture
Summary:
In SMP mode, task scheduling still follows the preemptive and time-slice round-robin strategy based on different priorities, which is no different from the single-core architecture’s task scheduling.
The difference is that the SMP version kernel uses a separate scheduler for each core (i.e., each core has its own tick interrupt).
It is precisely because of this design, where each core has its own scheduler, that the scheduling strategy on a single core can be considered similar to that of a single-core architecture. The only difference is that it will consider the case where the core ID is configured as tskNO_AFFINITY.
The overall scheduling strategy can be summarized as:
Tasks that have specified a core ID will only run on the specified core.
When the core ID is configured as tskNO_AFFINITY, based on the kernel’s scheduling strategy, the task may run on any core.
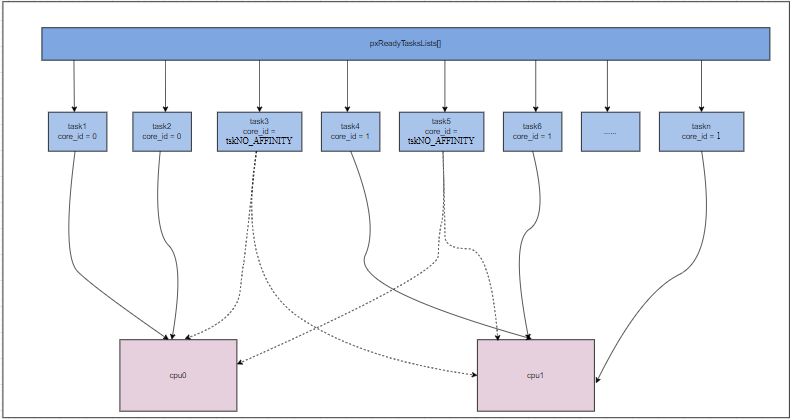
SMP dual-core scheduler
Task Priority:
For FreeRTOS systems, when creating a task, the higher the priority number set, the higher the task’s priority. Each time a task switch is executed, the system always selects the task with the highest current priority from the ready list to execute.
In SMP mode, each core independently schedules the tasks to be run. When a core selects a task, it chooses the highest-priority task that is ready to run and can run on that core.
The following conditions must be met for a task to be able to run on a core:
The task’s affinity is compatible, the task has been assigned to the current core or the core ID is configured as tskNO_AFFINITY
The task is not currently running on another core.
It’s worth noting that two tasks with the highest priority may not always be run by the scheduler, as the task’s core affinity configuration must also be taken into account.
For example (note that the priority levels are seen from the kernel’s perspective, so the higher the number, the higher the priority):
Task A has a priority of 8 and is assigned to core 0
Task B has a priority of 7 and is assigned to core 0
Task C has a priority of 6 and is assigned to core 1
After scheduling, Task A will run on core 0, and Task C will run on core 1. Even though Task B is the second-highest priority task, it will not be executed (because it is only assigned to core 0).
Task Preemption:
In a single-core FreeRTOS system, if a higher-priority task is ready to run, the scheduler can preempt the currently running task. In an SMP system, if the scheduler determines that a higher-priority task can run on a particular core, the scheduler can preempt the core individually.
However, in some cases, a higher-priority ready task can run on multiple cores. In this case, the scheduler will only preempt one core. Even if there are multiple cores that can be preempted, the scheduler will always prioritize the current core.
For example, given the following tasks:
Task A has a priority of 6 and is currently running on core 0.
Task B has a priority of 7 and is currently running on core 1.
Task C has a priority of 8, is not assigned to a fixed core, and has just been unblocked by task B.
So after scheduling, task A continues to run on core 0, and task C preempts task B. That is, a task with priority 6 runs on core 0, a task with priority 8 runs on core 1, and a task with priority 7 does not run.
Task Time Slice:
In single-core mode, if there are multiple ready tasks at the highest priority, the scheduler will round-robin among them, periodically switching between them.
However, in SMP kernel, a specific task may not be able to run on a specific core, so the time-slice round-robin strategy is different from single-core mode. The reason for this phenomenon may be:
The task is assigned to a different core.
The task is not assigned, but is already running on another core.
Based on this, when a core is searching for a task to run among all ready tasks, it may need to skip some tasks with the same priority or lower the priority to find a ready task that can run. The SMP kernel scheduler will ensure that the chosen task is moved to the end of the list, providing the best time-slice round-robin for tasks with the same priority. This way, in the next scheduling, the tasks that were not chosen will have a higher priority.
Note
To achieve ideal time-slice round-robin, it is recommended to assign all tasks with a specific priority (which requires perfect time allocation by the upper layer) to the same core.
tick Clock:
In SMP kernel, each core has its own tick interrupt, and they all receive tick interrupts at regular intervals and run independently. The tick interrupt period is the same for all cores, but they may not be synchronized.
It’s worth noting that the handling of tick interrupts on core 0 and core 1 is different.
The content on core 0 is consistent with single-core systems, and is primarily responsible for:
Incrementing the kernel’s tick count.
Checking if any tasks have timed out and are due to be unblocked, and if so, unblocking them and adding them to the ready list.
Checking if a time-slice round-robin is needed.
Executing application layer callback functions
Core 1 only checks if a task switch is needed and executes the application-provided tick hook function (if any).
Task Suspension and Resumption:
In SMP kernel, it is not possible to suspend the scheduler on multiple cores simultaneously. vTaskSuspendAll() and xTaskResumeAll() can only be called on a specific core.
When vTaskSuspendAll() is called on a particular core:
Only task switching is disabled on that core, but interrupts on that core can still be serviced.
The core will no longer respond to any blocking or manually triggered scheduling actions, and will not perform time-slicing.
When an interrupt unblocks a task on that core, if the task’s affinity is configured for that core, it will enter the core’s list of tasks to be executed. Any unassigned tasks or tasks with affinity configured for other cores can be scheduled on cores that are still running the scheduler.
When all cores’ schedulers are suspended, any tasks unblocked by an interrupt will enter the ready list of the core they are assigned to. If the task is not assigned, it will enter the ready list of the core that the interrupt was called on.
If the core is core 0, the tick counter will be paused, but the suspended tick count will increment, and clock interrupts will still occur to execute the application’s clock.
When xTaskResumeAll() is called on a particular core:
Any tasks that were added to the core’s ready list will resume running;
If the core is core 0, the suspended tick count will be compensated for.
Idle Task:
In SMP systems, a separate idle task is created for each core, and each core’s idle task is the same as in single-core mode.
Resource Synchronization in FreeRTOS SMP Architecture
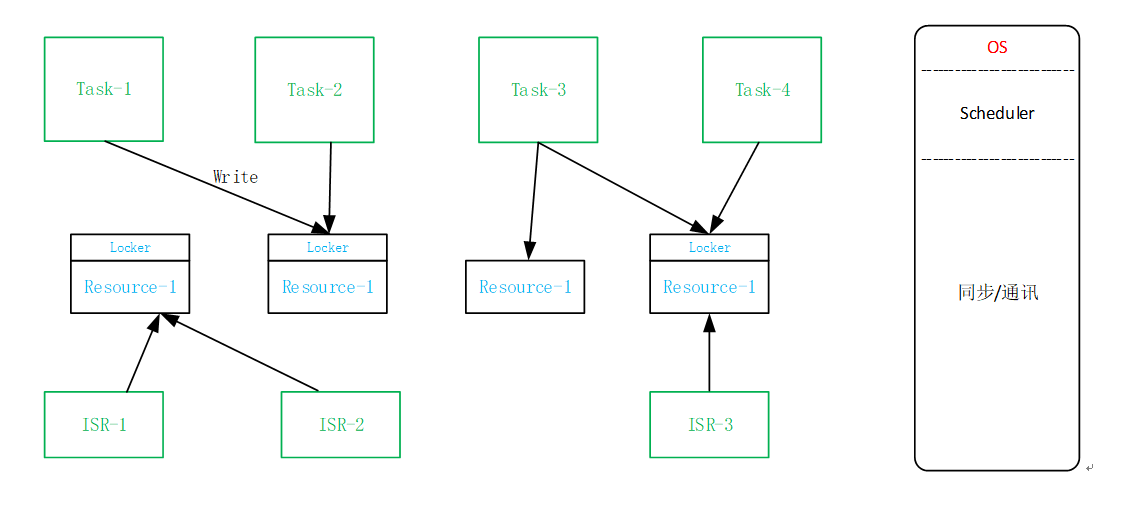
SMP Architecture Shared Resource Synchronization
Task-to-Task Shared Resource Synchronization:
Semaphore
Mutex
Disabling Scheduling
ISR-to-ISR Shared Resource Synchronization:
SpinLock
Task-to-ISR Shared Resource Synchronization:
SpinLock
FreeRTOS SMP Architecture: Spin Locks and Critical Sections
SpinLock:
In SMP systems, access to shared resources relies on spin locks.
Implementation Principle
A spin lock is a type of lock used to protect shared resources in multi-threaded environments. When a thread tries to acquire a lock, if the lock is already held by another thread, the current thread will wait indefinitely until it can acquire the lock.
Spin locks are typically used in multi-core systems. The key point of implementation is to ensure atomicity. For different hardware architectures, atomic instructions provided by the architecture are usually used to implement spin locks.
Dynamic Spin Locks and Static Spin Locks
To improve system performance while ensuring protection of shared resources, spin locks are divided into static spin locks and dynamic spin locks. All spin lock resources are located in a fixed memory segment, sram_spinlock_section, controlled by the macro CONFIG_SPINLOCK_SECTION.
Static spin locks are provided for application layer use, and their usage is described in the following chapters. Dynamic spin locks are used by the kernel, and a dynamic spin lock is allocated for each kernel object.
Note
It’s worth noting that dynamic spin locks are bound to the allocated object, and the dynamic spin lock resource will only be released when the kernel object is released. For example, when a queue resource is allocated, the kernel will allocate a dynamic spin lock for it, and the dynamic spin lock resource will only be released when the queue is destroyed.
SpinLock API
The code implementation for spin locks is located in the middleware/driver/spinlock directory, and the current spin lock API includes the following functions:
Acquiring a spin lock, and if not acquired, the core will spin:
void spin_lock(volatile spinlock_t *lock)
Checking if the current spin lock is already occupied, and if not, acquiring the lock.:
int spin_trylock(volatile spinlock_t *lock) Return value: 1: Spin lock is already occupied 0: Spin lock is not occupied
Releasing a spin lock:
void spin_unlock(volatile spinlock_t *lock)
Masking interrupts and acquiring a spin lock:
uint32_t _spin_lock_irqsave(spinlock_t *lock)
Releasing a spin lock and restoring interrupts:
void _spin_unlock_irqrestore(spinlock_t *lock, uint32_t flags)
Note
The current spin lock supports a nesting mechanism, with a maximum of 256 levels of nesting.
Using Spin Locks
The application layer can use spin locks by following these steps:
Initializing a spin lock:
#ifdef CONFIG_SOC_SMP #include "spinlock.h" static SPINLOCK_SECTION volatile spinlock_t test_spin_lock = SPIN_LOCK_INIT; #endif // CONFIG_SOC_SMP
Acquiring a spin lock:
spin_lock(&test_spin_lock);
Releasing a spin lock:
spin_unlock(&test_spin_lock);
Note
The spin lock must be placed in the SPINLOCK_SECTION segment
Critical Sections:
In the AMP architecture, FreeRTOS’s critical section operation is to mask interrupts to prevent preemption and interrupt service within the critical section, ensuring that the task or ISR entering the critical section is the only entity accessing shared resources.
In SMP architecture, the critical section operation becomes more complex, and simply disabling interrupts is not enough to protect shared resources such as memory and peripherals, as other cores can still access these shared resources.
Therefore, the critical section in SMP architecture is a combination of interrupt masking and spin locks.
Using Critical Sections:
There are two ways to use critical sections:
1.The application layer directly calls the API provided by the OS adaptation layer, in which case all callers share a single lock:
Enter Critical Section:
uint32_t rtos_enter_critical( void ) { uint32_t flags = rtos_disable_int(); spin_lock(&rtos_spin_lock); return flags; }
Exit Critical Section:
void rtos_exit_critical( uint32_t state ) { spin_unlock(&rtos_spin_lock); rtos_enable_int(state); }
2.The module defines its own lock and encapsulates it in the following way, using its own lock:
#include "spinlock.h"
static SPINLOCK_SECTION volatile spinlock_t xx_spin_lock = SPIN_LOCK_INIT;
static inline uint32_t xx_enter_critical()
{
uint32_t flags = rtos_disable_int();
#ifdef CONFIG_FREERTOS_SMP
spin_lock(&xx_spin_lock);
#endif // CONFIG_FREERTOS_SMP
return flags;
}
static inline void xx_exit_critical(uint32_t flags)
{
#ifdef CONFIG_FREERTOS_SMP
spin_unlock(&xx_spin_lock);
#endif // CONFIG_FREERTOS_SMP
rtos_enable_int(flags);
}
Note
Recommendation: If the protected resource is accessed infrequently, method 1 can be used. If the resource is frequently accessed by the upper layer, method 2 can be used. Additionally, unless it is certain that critical protection is necessary, it is recommended to use a mutex instead of a critical section
Notes
Due to the critical section disabling interrupts and acquiring a spin lock, the following restrictions should be noted when using critical sections:
The critical section should be as short as possible. If the critical section takes too long (e.g., exceeding one tick), it will affect the system’s scheduling performance.
Do not call FreeRTOS API within a critical section
Do not call any blocking functions within a critical section
If possible, push as many execution operations or event handling as possible outside of the critical section
A typical critical section should only access a small number of data structures or hardware registers
API Introduction in FreeRTOS SMP Architecture
In general, the application layer should not directly call the APIs provided by the kernel, but instead call the APIs provided by the OS adaptation layer in the SDK. The adaptation layer’s source code is located in: components/bk_rtos/freertos/v10/rtos_pub_smp.c, and the corresponding header file is located in: os/os.h.
Please refer to:
FreeRTOS SMP Architecture Project Configuration
The default app project in the BK7258 ap directory is SMP architecture, and the project configuration is as follows:
CONFIG_CPU_CNT=2 CONFIG_SOC_SMP=y CONFIG_FREERTOS_SMP=y CONFIG_SPINLOCK_SECTION=y